
Ultralytics YoloV5
YOLO: The “Bright Star” of Object Detection
As a core field of AI vision, object detection can accurately identify and locate targets in images or video frames. Since the emergence of YOLO, this field has undergone a revolutionary transformation.
In 2015, Joseph Redmon, a PhD student at the University of Washington, first proposed the YOLO (You Only Look Once) object detection algorithm. This algorithm cleverly integrates region proposal and classification into a single neural network, completely innovating real-time object detection, significantly reducing computation time, and enabling efficient end-to-end learning.
After leading the maintenance of YOLOv3, Joseph Redmon stopped developing subsequent versions due to concerns that his research might be used for military or malicious purposes (e.g., autonomous weapons like drones, surveillance systems, etc.), which conflicted with his academic original intention. He believed that AI technology should serve social welfare rather than exacerbate security risks.
The Logic Behind YOLO Algorithm
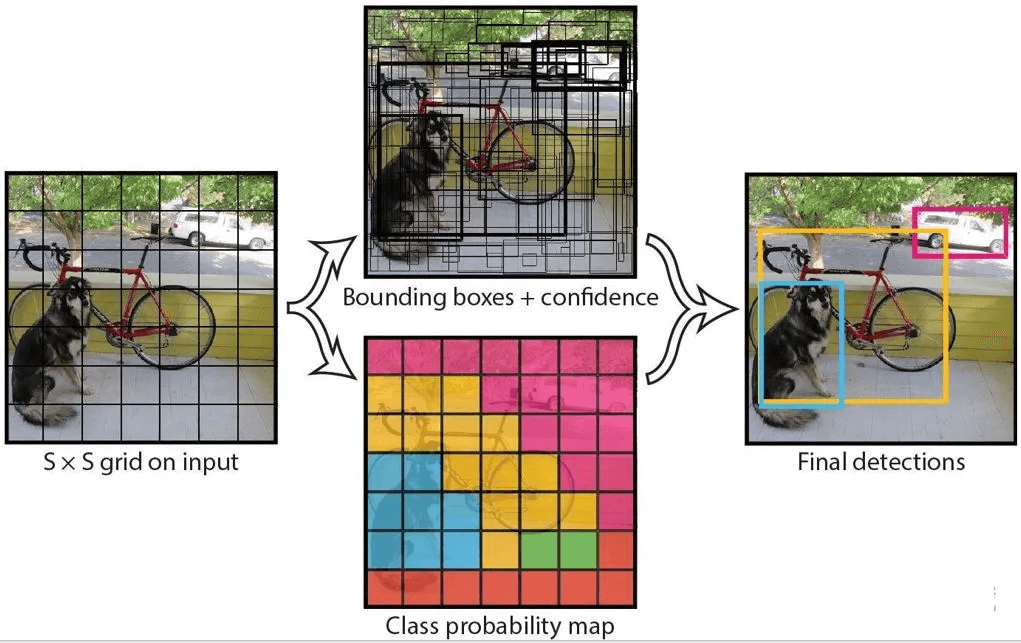
The YOLO algorithm divides the input image into S×S grid cells, just like cutting a cake. It then uses convolution to extract features, generating a feature map. Each grid cell in the feature map acts like a small detective, corresponding to a grid cell in the original image and responsible for finding targets. If the center of a target falls within a grid cell, the “detective” predicts the target’s size, shape, and category. This is YOLO’s core idea—simple and straightforward.
| Traditional Algorithms (e.g., R-CNN) | YOLO Algorithm |
|---|---|
| Step-by-step processing: First find candidate regions, then classify | One-step processing: Directly predict in grids |
| May take seconds to process one image | Only 0.01 seconds to process one image (real-time) |
| Like finding targets with a magnifying glass—slow but potentially more accurate | Like scanning with eyes—fast and sufficiently accurate |
Unveiling the YOLO Family
Since its debut in 2015, YOLO has evolved from version V1 to V11 through multiple iterations. Each version has unique features and is suitable for different scenarios.
Detailed Introduction to Each Model:

| Version | Release Date | Key Features & Improvements |
|---|---|---|
| YOLOv1 | 2015 | First single forward pass, fast detection speed; low small object detection accuracy and high positioning error |
| YOLOv2 | 2016 | Introduced anchor boxes, improved small object detection, and enhanced model robustness |
| YOLOv3 | 2018 | Used Darknet-53, introduced FPN (Feature Pyramid Network), and improved detection capability for multi-scale targets |
| YOLOv4 | 2020 | Integrated CSP connections and Mosaic data augmentation, balancing training strategies and inference costs |
| YOLOv5 | June 2020 | Developed with PyTorch, significantly improved usability and performance, becoming a popular choice |
| YOLOv6 | 2022 | Developed by Meituan, optimized model structure and training strategies to improve detection accuracy and speed |
| YOLOv7 | 2022 | Improved balance between lightweight design and accuracy, introduced new training technologies and optimization methods |
| YOLOv8 | 2023 | Anchor-free detection head, advanced backbone network, optimized accuracy and speed, supporting multiple vision tasks |
| YOLOv9 | 2024 | Introduced automated training and optimization technologies to improve model adaptability and detection performance |
| YOLOv10 | 2024 | Ultra-large-scale model, enhanced generalization ability and real-time performance for complex scenarios |
| YOLOv11 | October 2024 | Innovative model structure and training methods, improved detection accuracy and efficiency |
Why Choose YOLOv5?
For fast object detection after capturing camera images, YOLOv5 is an excellent choice due to the following features:
- High Accuracy & Efficiency: YOLOv5 maintains high detection accuracy while offering extremely fast inference speed. It can quickly detect targets in real-time video streams, making it suitable for scenarios requiring rapid processing of large amounts of image data.
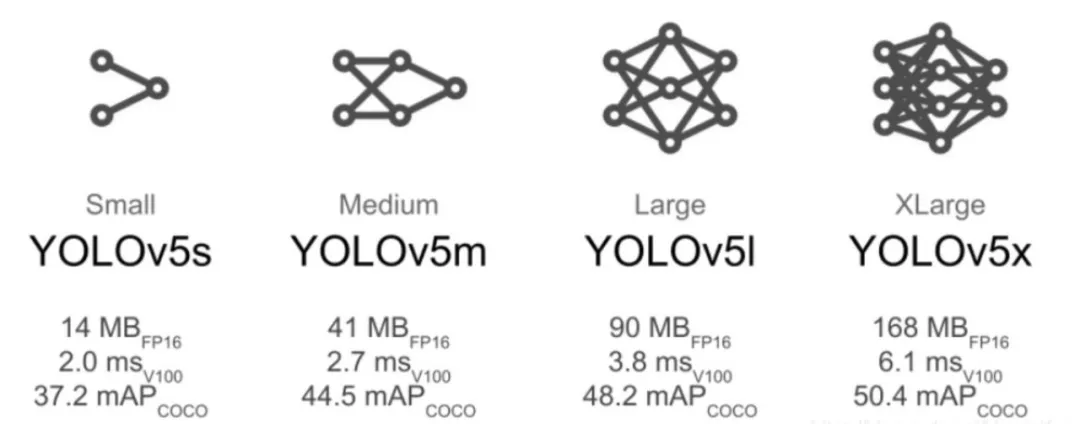
- Multi-version Support: YOLOv5 provides multiple versions (e.g., n, s, m, l, x). Users can choose models of different sizes based on their needs. For resource-constrained devices (e.g., mobile devices), lightweight versions like YOLOv5n are ideal; for high-precision requirements, larger versions like YOLOv5x are recommended.
- Easy Deployment: Developed based on PyTorch—a popular deep learning framework with strong community support and abundant resources—YOLOv5 features readable and modifiable code for customized development. Its clear code structure and complete training/inference scripts simplify the process from model training to deployment. It also supports multiple export formats (e.g., ONNX, TorchScript) for cross-platform deployment.
- Active Community: YOLOv5 has a highly active community, where developers can easily find numerous tutorials, pre-trained models, and use cases. This allows beginners to get started quickly and receive timely help when encountering issues.
MiniCPM-V
A GPT-4o Level MLLM for Single Image, Multi Image and High-FPS Video Understanding on Your Phone